Cuando tienes que abordar un proyecto tan grande como DIA4RA, cuyo objetivo es el de dotar de inteligencia a un robot humanoide para que sea capaz de asistir y ayudar a pacientes con Alzheimer, un punto clave consiste en elegir qué herramientas se van a emplear para conseguirlo.
Creemos que, para que comprendáis por completo las dimensiones del proyecto, debéis conocerlas (o, por lo menos, que os suenen). Así pues, vamos a aprovechar el diario para compartir con vosotros una serie de artículos en los que se pretende tanto discutir las elecciones realizadas como mostrar una introducción al funcionamiento de dichas herramientas.
ROS
Por un lado se necesita un framework que permita distribuir la información procedente de los múltiples sensores del robot y enviar órdenes a sus actuadores. Para conseguir esto, se decidió utilizar ROS (como dijimos en artículos anteriores, significa Robot Operating System). Puede considerarse como la solución más robusta y potente, en cuanto a las posibilidades que ofrece, cuando hay que trabajar a nivel profesional con componentes robóticos.
Además en datahack contamos con la colaboración del grupo de Robótica de la URJC de Fuenlabrada. Ellos disponen de amplia experiencia en este ámbito avalada por sus publicaciones, su contribución a proyectos Open-Source por sus continuas participaciones en congresos y torneos internacionales como Robocup, iROS, etc.
Tensorflow
Por otro lado es necesario disponer de otro framework con el que desarrollar los algoritmos que implementarán la inteligencia de AIDA (como dijimos en el primer post del diario, es nuestro robot y sus siglas significan Artificial Intelligence Datahack Ambassador). Para este propósito nos decantamos por Tensorflow debido al fuerte impulso que está recibiendo por parte de Google y de la comunidad de investigadores en Inteligencia Artificial.
Google Cloud
Además, tuvimos que decidir entre:
si adquirir la infraestructura de máquinas equipadas con GPU’s potentes para entrenar todos los modelos que necesita el robot y ponerlos en producción
si era preferible emplear el Cloud de alguno de los grandes proveedores, que nos permitiese desplegar el entorno necesario para entrenar algoritmos y realizar las predicciones con los modelos generados.
Hay que tener en cuenta que, cuando el robot sea plenamente funcional, deberá contar con al menos 8 modelos predictivos ejecutándose en paralelo. A eso habrá que sumar el planificador global de tareas que controlará el comportamiento de AIDA, así como los recursos necesarios para la gestión de su Sistema Operativo y de los demonios de ROS.
Nuestro compañero Alejandro se encargó de implementar una arquitectura hardware que soportase todos los requisitos tanto para el entrenamiento como para la inferencia.
En paralelo, iniciamos contactos con Nvidia y Google con el objetivo de presentarles nuestro proyecto y buscar distintas formas de colaboración. Como resultado, pasamos a formar parte tanto del programa “Inception” de Nvidia, con el que proporcionan recursos, soporte y promoción, como del programa “Google Cloud for Startups” en el que entre otros beneficios se dispone de créditos para entrenar y servir modelos empleando la infraestructura de Google Cloud Platform.
Teniendo todo esto en cuenta, la aproximación que hemos tomado ha sido la de “prototipar” el código de los algoritmos en nuestras máquinas de trabajo, que disponen de tarjetas GPU de Nvidia. Luego hemos adaptado dicho código a los requisitos de Tensorflow para que pueda ser entrenado empleando el Cloud. Esto nos da la flexibilidad de poder utilizar el mismo código tanto en una arquitectura on-premise como en la nube.
¡Seguro que ahora quieres saber más sobre cómo aplicamos estas herramientas en el proyecto!
Pues no temas, porque vamos a desarrollar todo esto un poquito más (en la sección DIA4RA para programadores, porque la cosa se pone un poco más técnica). Y es que, como puedes comprobar, el proyecto DIA4RA ya lleva un tiempo corriendo. No ha empezado, ni mucho menos, con la llegada de AIDA.
Por eso decidimos hacer esta serie de artículos “flashback” dedicados a las herramientas de programación que se emplearán en DIA4RA. Comenzaremos mostrando la estructura que deberá tener el código de Tensorflow para que pueda ser entrenado de forma distribuida y servido en el Cloud. El siguiente paso consistirá en presentar los principales componentes de ROS, para finalizar enseñando cómo integrarlos con los modelos de Tensorflow. De esta forma, os mostraremos el recorrido cuya meta es la de combinar modelos predictivos de Deep Learning con Robótica.
Y es que, una vez realizada esta introducción, empieza lo realmente divertido para nosotros, ponernos manos a la obra con la parte técnica.
El proyecto empresarial de DATAHACK CONSULTING SL., denominado “DESARROLLO DE INTELIGENCIA ARTIFICIAL EN ROBOTS APLICADOS AL TRATAMIENTO DEL ALZHEIMER Y LA DEMENCIA” y número de expediente 00104725 / SNEO-20171211 ha sido subvencionado por el CENTRO PARA EL DESARROLLO TECNOLÓGICO INDUSTRIAL (CDTI)
Gracias al Master en Big Data Analytics 100% Online tendrás amplios conocimientos sobre las herramientas y técnicas analíticas necesarias para la modelización de los principales retos de negocio, con el fin de mejorar la toma de decisiones a través de los datos y el conocimiento.
Con motivo de la semana de la educación que tuvo lugar en Feria de Madrid, Aitor Juan Farragut, miembro del equipo de Datahack, fue invitado como ponente en el panel de expertos en Machine Learning organizado por Expoelearning en su XVII Congreso Internacional.
Proyectos de chatbots y robótica
Tuvimos la oportunidad de presentar nuestros proyectos relacionados con chatbots y robótica y su posible aplicación al sector de la educación online. Resaltamos la importancia que las organizaciones han de dar a la gestión del tiempo y la versatilidad que ofrecen los chatbots para realizar tareas repetitivas y automáticas. El objetivo es dejar a las máquinas hacer aquello para lo que son mejores y permitir a las personas crecer a nivel humano, formarse y aportar nuevas oportunidades a la compañía en este contexto digitalizado.
Por otro lado, presentamos nuestro proyecto de robótica Dia4ras, orientado al ámbito asistencial. La presentación del proyecto giró en torno a las habilidades en las que podemos entrenar a un robot con técnicas basadas en Inteligencia Artificial y del potencial que tienen para asistir y complementar al ser humano en tareas que nunca antes nos habíamos planteado.
La charla subrayó en todo momento la importancia del uso y adaptación a las nuevas tecnologías y la formación digital del ser humano, sin olvidar que este debe estar presente en todo momento y buscar el equilibrio entre la tecnología y la persona, además de la ética.
Las organizaciones han de formarse y adaptarse al mundo digital. Debemos dejar a las máquinas hacer aquello en lo que son mejores y con el tiempo que nos queda disponible, debemos aportar nuevo valor a la compañía y a nuestro entorno. Crear sinergias en nuestros equipos y ser embajadores de marca de nuestras organizaciones. Porque el color en el cambio lo ponemos las personas.
La tarde del lunes 12 de junio tuvo lugar innodata 2017, una jornada en la que hicimos un repaso de algunas de las tendencias actuales y de futuro del Big Data. Para ello, salimos de nuestras oficinas de Calle López de Hoyos y nos trasladamos a Campus Madrid, un espacio más idóneo para un evento de tal envergadura .
La jornada constó de dos partes, la primera protagonizada por algunos de los profesores de datahack. En la que realizaron breves charlas sobre diferentes temas como arquitectura de datos, Deep Learning o Robótica. La segunda parte consistió en una mesa redonda titulada "¿Hacia dónde va la innovación?". En la que participaron altos cargos de innovación y Big Data a nivel nacional.
Las ponencias del innodata 2017
Mario Renau fue el encargado de empezar la sesión con "Evolución a Arquitecturas Datacentric". Haciendo una analogía con el alpinismo, su gran afición, para impartir la charla. Habló de diferentes temas como los sistemas informacionales y el Business Intelligence, con el que según Mario, se pueden "realizar consultas eficientes de grandes cantidades de datos". Ya que facilita la recogida de información para generar informes. O de los inconvenientes que supone un Data Lake y otros aspectos de la Arquitectura Data Centric.
Inteligencia artificial aplicada en robots
Le siguió Juan Cañada con su conferencia "Simulación por ordenador para entrenar sistemas de Inteligencia Artificial". En la que destacó lo importantes que son los robots en nuestra vida cotidiana que están presentes en más objetos de lo que pensamos. Se ha tenido que recurrir a la simulación por ordenador para hacerlos "inteligentes" y capaces de realizar tareas más complejas. Con la visualización se consigue "ensayar" antes de llevar a la práctica el funcionamiento de los robots y evitar así los errores que pueden ocasionar.
La tercera y última conferencia fue a cargo de Rubén Martínez, titulada: "Deep Learning aplicado a robótica: construye tu propio Bender". Que constó de dos partes, la primera una explicación técnica y la segunda fueron dos demos del robot Yaco. En la parte técnica se vieron las Redes Neuronales Convulocionales, empleadas por ejemplo en los filtros de imágenes o en programas de retoque fotográfico como Photoshop. Y el framework que se emplea para la programación del robot, ROS (Robot Operating System) que sirve para controlar los componentes del robot. En las demos, se realizó una en directo en la que se demostró cómo Yaco detecta caras, siendo capaz de saber si el individuo es hombre o mujer y cuáles son sus emociones. Además de un video en el que Yaco detecta objetos que se encuentran próximos a él.
¿Hacia dónde va la innovación?
La mesa redonda estuvo moderada por Lourdes Hernández Vozmediano, CEO de datahack. En ella intervinieron Pablo Montoliu, Chief Information & Innovation Officer de AON. Juan Antonio Torrero Big Data Innovation Leader de Orange España. Y Federico Sanz Sobrino, Deputy Director-Digitalization and Projects Evaluation de Repsol.
En la que se vieron algunas de las aplicaciones que se realizan de la gran cantidad de datos en empresas como AON, Orange España y Repsol. En la que se vio el cambio de paradigma a la toma de decisiones basadas en datos y no en las decisiones de un directivo. También se trataron otros temas como el cyberataque que se produjo hace unas semanas y las consecuencias que ha tenido en el mantenimiento de la seguridad. Y de posibles tendencias de futuro como mercados de datos, o el cambio de la normativa de privacidad en 2018, que cambiará la forma de aprovechar los datos.
La jornada finalizó con una breve sesión de networking con pizzas y refrescos para todos los asistentes, todo ello por cortesía de Stratio. El evento fue recogido por Blanca Tulleida en dibujos de Dibu2pia. Que durante cada actividad del innodata 2017 estuvo dibujando todo lo que se acontecía en el stage de Campus Madrid.
Dejando a un lado el Internet Of Things y las Smart Cities, otro de los aspectos que facilita el análisis rápido de grandes volúmenes de datos es el deep learning y la inteligencia artificial, software capaz de analizar datos en tiempo real y adelantarse a futuros problemas, aprendiendo a sacar sus propias conclusiones sin necesidad de un programador.
La prueba de que el sector de la inteligencia artificial es uno de los más prometedores en la tecnología de la información es el interés de las grandes empresas por adquirir startups del sector, como demuestra la creciente actividad de Google, Facebook, Apple, Intel o Amazon en este negocio, con cuatro compras destacadas en lo que llevamos de año.
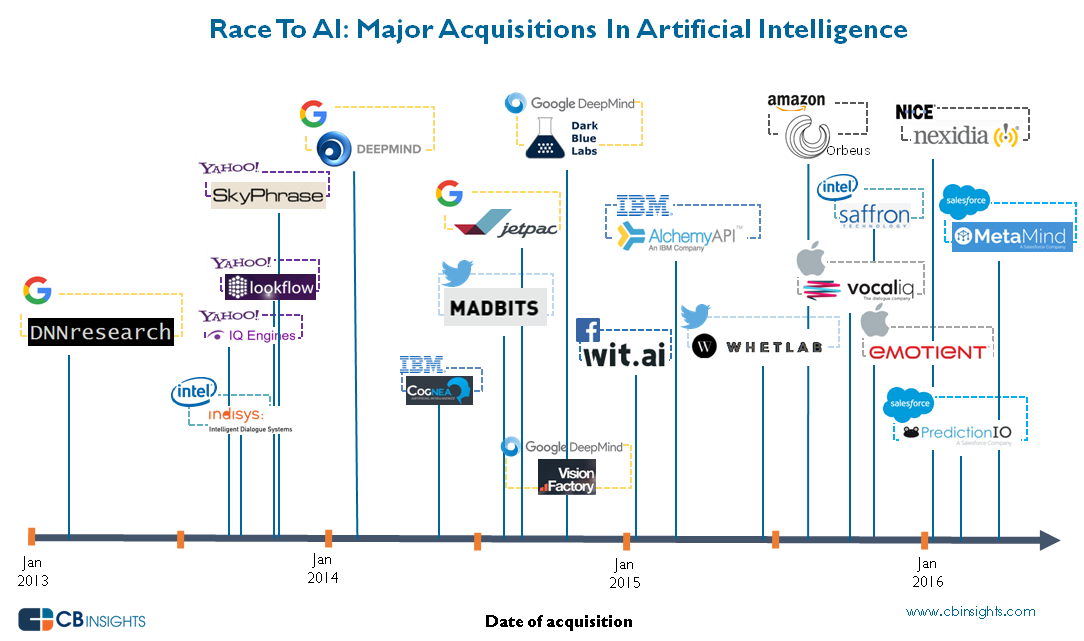
Tal como indica el interesante artículo de CB Insights, más de 20 empresas privadas dedicadas a tecnologías avanzadas de inteligencia artificial han sido adquiridas por las grandes corporaciones en los últimos 3 años.
Inteligencia Artificial - línea cronológica de adquisiciones / FUENTE: CB Insights
Atendiendo a los rumores sobre un nuevo algoritmo para el buscador de Google capaz de reconfigurarse a sí mismo en función de las necesidades, el rey de los buscadores destaca como líder de la inversión en Inteligencia Artificial. De hecho, es el que más empresas ha adquirido, un 25% del total de empresas compradas. Entre estas incorporaciones destacan la compra en 2013 de DNNResearch, empresa especializada en Deep Learning y redes neuronales y fundada en la Universidad de Toronto, que le permitió a Google mejorar su buscador de imágenes. También destaca la adquisición en 2014 de la compañía británica DeepMind Technologies por unos 600 millones de dólares, cuya tecnología pudimos ver todos hace unos meses cuando el ordenador venció al campeón mundial del juego tradicional chino “Go”.
Amazon es otra de las multinacionales que compiten en el sector de la inteligencia artificial, enfocando su atención en el machine learning, con la adquisición de la californiana Orbeus. Salesforce se apuntó a la carrera en 2016, con la adquisición de dos compañías: MetaMind y el servidor de código abierto para machine learning ProductionIO.
Otras adquisiciones son, por ejemplo, Vision Factory, empresa dedicada al reconocimiento de textos y objetos mediante deep learning, por parte de Facebook; o Whetlab y Madbits por Twitter, dedicadas, respectivamente, a acelerar y mejorar los procesos de machine learning y a la identificación del contenido de imágenes mediante algoritmos de Deep Learning.
Si la inteligencia artificial es tu campo de interés, apúntate a nuestro máster Big Data, que culmina con un módulo de algoritmos avanzados de Deep Learning.
Machine learning es una de las palabras de moda en el mundo del Big Data. Es como el sexo de los adolescentes estadounidenses, todo el mundo habla de ello, todos dicen haberlo hecho, pero realmente ninguno sabe lo que es.
Según SAP, uno de los principales productores mundiales de software para la gestión de procesos de negocio, lo define como: "Un subconjunto de inteligencia artificial (IA). Se centra en enseñar a las computadoras a aprender de los datos y mejorar con la experiencia -en lugar de ser explícitamente programadas para hacerlo- En Machine Learning los algoritmos se capacitan para encontrar patrones y correlaciones en grandes data sets y para tomar las mejores decisiones y previsiones basadas en ese análisis".
A continuación, trataremos de esclarecer la definición anterior.
La mayoría de los programas informáticos están compuestos por una serie de órdenes ejecutables. Los programas conocen lo que han de hacer: abrir un fichero, buscar, comparar, ordenar, agregar, y muchas operaciones lógicas y matemáticas por complejas que sean.
En Machine Learning se ofrecen una serie de programas que a través de la recolección y el análisis de los datos existentes pueden predecir el comportamientos futuro de los programas.
Las tres C’s del Machine Learning
Existen tres categorías bien definidas de técnicas de explotación de datos, los filtros colaborativos empleados para realizar recomendaciones, el clustering y los clasificadores.
Machine Learning: filtros colaborativos
Es una técnica utilizada para realizar recomendaciones. Uno de los primeros en aplicar esta técnica fue Amazon. Analiza los gustos de las personas y los aprende para poder sugerirle nuevos gustos. Es muy útil para ayudar a los usuarios a navegar por la red, mostrando los temas afines a sus intereses y gustos. Los filtros colaborativos no están limitados por el tipo de datos con los que trabajan en un momento determinado, por lo que son muy útiles trabajando en dominios distintos.
Por ejemplo, a través del análisis de los gustos de una persona al calificar un producto audiovisual como un largometraje, el programa puede adivinar qué nota le pondría a otra serie o cinta que aún no ha clasificado.
Machine Learning - Ejemplos de Clustering
Machine Learning: Clustering
El Clustering descubre agrupaciones en los datos que no existían previamente. Busca encontrar relaciones entre variables descriptivas de manera automática. Puede, por ejemplo, encontrar relaciones entre publicaciones nuevas que aparentemente no tienen ningún patrón común, o analizar grupos de píxeles en varias imágenes que se relacionan con ciertos objetos.
Tanto los filtros colaborativos como el clustering son técnicas no supervisadas; no es necesario disponer de ninguna información previa de los datos.
Machine Learning: clasificadores
Los clasificadores son una forma de aprendizaje supervisado. Usan una serie de registros identificados mediante un etiquetado conocido. A partir de ellos, el clasificador puede etiquetar nuevos registros de manera autónoma. Algunos usos de estos clasificadores pueden ser el etiquetado del correo Spam a partir de otros mensajes previamente clasificados, o la identificación de tumores malignos o benignos a partir de otros ya etiquetados previamente
Como vemos la utilidad del Machine Learning es fantástica y casi mágica, ahorrando mucho trabajo.
Gracias al Master en Big Data Analytics 100% Online tendrás amplios conocimientos sobre las herramientas y técnicas analíticas necesarias para la modelización de los principales retos de negocio, con el fin de mejorar la toma de decisiones a través de los datos y el conocimiento.
Resumen de privacidad
Esta web utiliza cookies para que podamos ofrecerte la mejor experiencia de usuario posible. La información de las cookies se almacena en tu navegador y realiza funciones tales como reconocerte cuando vuelves a nuestra web o ayudar a nuestro equipo a comprender qué secciones de la web encuentras más interesantes y útiles.
Cookies estrictamente necesarias
Propiedad
Cookie
Finalidad
Plazo
datahack.es
_btrid
Cookie necesaria para la utilización de las opciones y servicios del sitio web
en un año
datahack.es
_gat_UA-32658908
-1
Cookie necesaria para la utilización de las opciones y servicios del sitio web
Sesión
google.com
__Secure-1PAPISI
D
Cookie necesaria para la utilización de las opciones y servicios del sitio web
en 2 años
google.com
__Secure-1PSID
Cookie necesaria para la utilización de las opciones y servicios del sitio web
en 2 años
google.com
__Secure-3PSIDC
C
Cookie necesaria para la utilización de las opciones y servicios del sitio web
en un año
Si desactivas esta cookie no podremos guardar tus preferencias. Esto significa que cada vez que visites esta web tendrás que activar o desactivar las cookies de nuevo.
Cookies de terceros
Propiedad
Cookie
Finalidad
Plazo
datahack.es
_ga
ID utiliza para identificar a los usuarios
en 2 años
datahack.es
_gid
ID utiliza para identificar a los usuarios durante 24 horas después de la última actividad
en 20 horas
google.com
__Secure-3PAPISI
D
Estas cookies se utilizan para entregar anuncios más relevantes para usted y sus intereses.
en 2 años
google.com
__Secure-3PSID
Estas cookies se utilizan para entregar anuncios más relevantes para usted y sus intereses.
en 2 años
Publicitarias
Propiedad
Cookie
Finalidad
Plazo
datahack.es
_fbp
Utilizado por Facebook para ofrecer una serie de productos tales como publicidad, ofertas en tiempo real de anunciantes terceros
en 3 meses
datahack.es
_gcl_au
Utilizado por Google AdSense para experimentar con la publicidad a través de la eficiencia de sitios web que utilizan sus servicios.
en 3 meses
google.com
APISID
Descargar ciertas herramientas de Google y guardar ciertas preferencias, por ejemplo, el número de resultados de la búsqueda por hoja o la activación del filtro SafeSearch. Ajusta los anuncios que aparecen en la búsqueda de Google.
en 2 años
google.com
HSID
Descargar ciertas herramientas de Google y guardar ciertas preferencias, por ejemplo, el número de resultados de la búsqueda por hoja o la activación del filtro SafeSearch. Ajusta los anuncios que aparecen en la búsqueda de Google.
en 2 años
google.com
SAPISID
Descargar ciertas herramientas de Google y guardar ciertas preferencias, por ejemplo, el número de resultados de la búsqueda por hoja o la activación del filtro SafeSearch. Ajusta los anuncios que aparecen en la búsqueda de Google.
en 2 años
google.com
SID
Descargar ciertas herramientas de Google y guardar ciertas preferencias, por ejemplo, el número de resultados de la búsqueda por hoja o la activación del filtro SafeSearch. Ajusta los anuncios que aparecen en la búsqueda de Google.
en 2 años
google.com
SIDCC
Descargar ciertas herramientas de Google y guardar ciertas preferencias, por ejemplo, el número de resultados de la búsqueda por hoja o la activación del filtro SafeSearch. Ajusta los anuncios que aparecen en la búsqueda de Google.
en un año
google.com
SSID
Descarga ciertas herramientas de Google y guarda ciertas preferencias, por ejemplo, el número de resultados de búsqueda por página o la activación del filtro SafeSearch.
Ajusta los anuncios que aparecen en la Búsqueda de Google.
en 2 años
¡Por favor, activa primero las cookies estrictamente necesarias para que podamos guardar tus preferencias!
Cookies adicionales
Los servicios de terceros son ajenos al control del editor. Los proveedores pueden modificar en todo momento sus condiciones de servicio, finalidad y utilización de las cookies, etc.