Puede parecer extraño asociar la palabra “historia” a un campo que, por así decirlo, aún se está consolidando como es el Deep Learning. Pero lo cierto es que, para remontarnos a los inicios de esta aproximación a la Inteligencia Artificial, hay que retroceder hasta los años 40 del siglo pasado. Parece mentira, ¿verdad? Las razones por las que el Deep Learning parece algo tan reciente es porque, a lo largo de su historia, ha vivido etapas oscuras en cuanto a popularidad. También por haber sido rebautizado varias veces: solo en los últimos años ha sido referido mediante el término “Deep Learning”.
Creemos que conocer algo del contexto histórico de esta disciplina, que a todos nos atrae y nos trae de cabeza a partes iguales, ayudará a comprender mejor su base y sus fundamentos:
Tres grandes corrientes son el origen del Deep Learning
Podemos concretar cronológicamente tres etapas en las que, esto que hoy llamamos Deep Learning, acaparó buena parte de la atención de la sociedad científica de su tiempo:
Cibernética (entre los 40 y los 60)
Esta primera ola arrancó con los estudios sobre el aprendizaje biológico (McCulloch&Pitts, 1943 y Hebb, 1949) que a su vez dieron pie a la implementación de los mismos a través de los primeros modelos como por ejemplo el Perceptrón (Rosenblatt, 1958) que permitían el entrenamiento de una única neurona.
Conexionismo (entre 1980 y los 1995)
Fue en esta época en la que surgió el concepto de backpropagation (Rummelhart et al, 1986), que actualmente se utiliza de forma masiva en el entrenamiento de redes neuronales para calcular los pesos de las neuronas correspondientes a las distintas capas de las mismas.
Dado que, históricamente, algunos de los primeros modelos pretendían emular el aprendizaje biológico o, lo que es lo mismo, cómo ocurre el aprendizaje en el cerebro, el término Artificial Neural Networks (ANN) se ha ido ligando cada vez más al Deep Learning. No obstante, a pesar de que los modelos de Deep Learning están inspirados en el cerebro biológico (ya sea humano o animal) NO están diseñados para ser una representación realista del mismo.
Sí es cierto que el cerebro es la prueba fehaciente de que el comportamiento inteligente es posible y que, en principio, el camino más intuitivo a seguir es hacer ingeniería inversa de los principios computacionales que subyacen al mismo y duplicar de este modo su funcionalidad. En este aspecto cualquier modelo que sirviera como herramienta en esta compleja tarea sería de gran utilidad (como en el caso del trabajo de Hinton&Shallice, 1991)
Actualmente, el término “Deep Learning” no va de la mano con la perspectiva neurocientífica, sino más bien con el tipo de aprendizaje que propone, a través de múltiples niveles de composición. Hay que pensar que esta disciplina tiene, entre sus objetivos, dar una solución al hecho de que hay máquinas que sobrepasan a nuestras mentes más brillantes en tareas formales o abstractas (como por ejemplo Deep Blue ganando al ajedrez a Garri Kasparov en 1997), pero que no pueden afrontar aquellas otras tareas para las cuales no es posible definir un conjunto formal de reglas que las determinen perfectamente (como por ejemplo reconocer palabras habladas o caras y objetos…).
Mediante el Deep Learning se propone que las máquinas sean capaces de entender el mundo a través de una jerarquía de conceptos, de manera que cada concepto se defina a través de sus relaciones con conceptos más simples. ¿Te imaginas un grafo que represente esta jerarquía cuántas capas tendría? Seguramente sería muy profundo, ¿verdad? Pues por ese motivo es que el Deep Learning recibe su nombre.
Gracias al Master en Big Data Analytics 100% Online tendrás amplios conocimientos sobre las herramientas y técnicas analíticas necesarias para la modelización de los principales retos de negocio, con el fin de mejorar la toma de decisiones a través de los datos y el conocimiento.
Retomamos el blog de AIDA con menos avances de los que desearíamos. Por un lado, desde el punto de vista de cada modelo de Deep Learning, nos hemos dado cuenta de que no estamos completamente satisfechos con casi ninguno de los conseguidos hasta el momento. Todos tienen algo que nos gustaría mejorar, cambiar o directamente volver a empezar. Todo ellos son poco viables en mayor o menor medida, ya que tenemos que estar siempre con un ojo en la planificación y, como dice nuestro compi Marcelo con mucha razón, si por nosotros fuera estaríamos un año con cada modelo: dándole vueltas, ampliando el dataset, tratando de introducir perturbaciones...
Problemas encontrados en los modelos de Deep Learning
Nos hemos encontrado (o más bien dado de bruces) con nuestras propias limitaciones y también las del Deep Learning, sobre las cuales otro de los compis de Labs (Rubén Martínez o @eldarsilver en Twitter) ha estado leyendo largo y tendido. La cantidad ingente de imágenes que requiere el resolver robustamente problemas del campo de la visión computacional hace que abordar modelos como el face recognition (reconocimiento facial) se convierta en poco más o menos que una odisea... Si es que no se dispone de una cantidad considerable de imágenes de cada sujeto en distintos entornos y en distintas circunstancias vitales.
Al final, nos encontramos con que abordar un problema de aprendizaje supervisado (aquel que consiste entrenar un modelo con ejemplos etiquetados del problema que queremos que resuelva) es muy difícil de conseguir mediante Deep Learning….Y si no es Deep Learning ¿qué hacemos? ¡buena pregunta! aunque compleja de responder...sería algo así como ¿cuál es el camino que lleva al futuro? ¿podrían ser las Spiking Neural Networks que desgranaremos en otro post?
En todo caso se acerca el final del 2018 y este es el balance que podemos extraer, estad con los ojos bien abiertos en el 2019 para no perderos por donde irán los tiros.
También hay cosas buenas: la máquina de estados finita
Igual que, con la transparencia que nos caracteriza, os transmitimos nuestras preocupaciones, no queremos despedirnos de vosotros este año sin compartir otro pequeño paso que no hubiera sido posible (de nuevo) sin los compañeros del Departamento de Robótica de la URJC: la implementación de una máquina de estados finita, simple pero funcional.
Por si alguien no ha tenido la oportunidad de disfrutar la asignatura de Teoría de Autómatas y Lenguajes Formales, básicamente el concepto alude a un modelo matemático que normalmente es representable mediante un grafo y que consta de un número finito de estados pudiendo estar en uno y solo uno en cada momento. Por supuesto, el paso de un estado a otro será posible como consecuencia de algún tipo de entrada externa que motive este cambio (o en lenguaje de Teoría de Autómatas: transición). De hecho una máquina de estados finita (o FSM: Finite State Machine) viene definida por su estado inicial, una lista de sus estados y las condiciones para que ocurra cada transición.
Si aun con todo, sigue sonando muy abstracto, pensad en las máquinas de vending, los ascensores o los candados con combinación...todos ellos son ejemplos cuya lógica interna responde a una FSM. Ahora bien, si queréis saber si hemos convertido a AIDA en una expendedora de gominolas y refrescos o si existe otro motivo mucho más interesante por el que queramos implantar en ella una máquina de estados…¡estad atentos a la siguiente entrada!. No os olvidéis de ser felices, ¡Feliz Navidad!
El proyecto empresarial de DATAHACK CONSULTING SL., denominado “DESARROLLO DE INTELIGENCIA ARTIFICIAL EN ROBOTS APLICADOS AL TRATAMIENTO DEL ALZHEIMER Y LA DEMENCIA” y número de expediente 00104725 / SNEO-20171211 ha sido subvencionado por el CENTRO PARA EL DESARROLLO TECNOLÓGICO INDUSTRIAL (CDTI)
Gracias al Master en Big Data Analytics 100% Online tendrás amplios conocimientos sobre las herramientas y técnicas analíticas necesarias para la modelización de los principales retos de negocio, con el fin de mejorar la toma de decisiones a través de los datos y el conocimiento.
La librería scikit-learn de Python sigue siendo una de las favoritas de los Kagglers (aunque Keras y Tensorflow ganan cada vez más adeptos). Igualmente, para todo el que desea iniciarse en Machine Learning utilizando Python como lenguaje de cabecera, la caja de herramientas que conforman numpy, pandas, matplotlib y scikit-learn se presenta como una manera razonablemente amigable de hacer los primeros pinitos.
Por ello, el hecho de que scikit-learn (biblioteca que encapsula distintas funciones de preprocesamiento de datos así como implementaciones de multitud de modelos orientados a resolver problemas tanto de aprendizaje supervisado como aprendizaje no supervisado) haya alcanzado la versión 0.20, es motivo de celebración. Qué mejor manera que celebrarlo con un pequeño post con algunas de las novedades que esta versión incorpora.
Empezando con la nueva versión de scikit-learn
Lo primero de todo es actualizar nuestra versión de scikit-learn para empezar a trastear con ella. Se recomienda utilizar algún entorno experimental (si tenéis instalado Anaconda podéis crearos uno con conda create y si no, pues con virtualenv env). Aquí, por ejemplo, utilizamos Anaconda y lo que haremos será simplemente listar nuestros entornos y activar aquel en el cual queremos actualizar la versión de scikit-learn.
Una de las primeras novedades que nos llamó la atención es la que afecta a la imputación o procedimiento. Mediante esta, se rellenaban aquellos huecos en el conjunto de datos propiciados por los valores missing (nulos, NA, NaN…como se prefiera llamar). La herramienta que scikit-learn proporcionaba para solventar esta tarea era principalmente el Imputer, si bien es cierto que presentaba algunas carencias. Por ejemplo: solo podía reemplazar valores missing o enteros o no permitía imputar un valor constante. Ahora SimpleImputer pone remedio a ambas carencias. Veamos un ejemplo:
Dataframes y features categóricas
Se define un dataframe de pandas con columnas de distintos tipos, en la columna disponibilidad, el último de los valores es u. Consideremos u el valor que queremos reemplazar y constant la estrategia a utilizar. Al aplicar el SimpleImputer definido sobre nuestro dataframe, vemos como el valor u ha sido reemplazado por la constante definida mediante fill_value: d.
Existen casos como el de OrdinalEncoder, en el que nuevas funcionalidades han sido añadidas un componente ya existente. Recordemos que este componente transforma las features con valores categóricos, asignando a cada uno de sus posibles valores un número entre 0 y el número de categorías - 1.
Veamos un ejemplo centrado únicamente en dos features categóricas:
Se define de nuevo un dataframe con las dos features categóricas que va a gestionar el OrdinalEncoder. Luego, este se entrena con este dataframe aprendiendo los posibles valores que pueden tomar dichas features y transformándolos en números (del tipo indicado mediante el parámetro dtype) en el rango de 0 a número de categorías - 1. Al examinar las categorías que ha detectado el OrdinalEncoder, apreciamos que lo que ha hecho es ordenarlas alfabéticamente y asignar un número empezando por 0 a cada una de ellas para cada una de las dos features. Pero ¿qué ocurre si aplicamos el OrdinalEncoder entrenado a nuevos datos?
Usando el OrdinalEncoder para entrenar nuevos datos
Si fichamos un manager para nuestro equipo, OrdinalEncoder será incapaz de hacer la transformación del nuevo dataframe. La razón de esto es que ha recibido una categoría (manager) con la cual no ha sido entrenado… Aquí es cuando viene al rescate el parámetro categories. Repitamos el ejemplo:
La gran diferencia es que, al definir el OrdinalEncoder, hemos indicado, mediante el parámetro categories, todos los posibles valores de nuestras features categóricas. Si no especificamos ningún valor para dicho parámetro, su valor por defecto será auto. Esto básicamente indica que los posibles valores de las features categóricas se inferirán de los datos con los que se entrene. Nota: en la versión 0.20.0 el uso del parámetro categories con otro valor que no sea el por defecto, dará un error. En la versión 0.20.1 está subsanado.
Otras novedades de interés
ColumnTransformer
Finalmente, mencionaremos una de las novedades que más nos ha gustado. Scikit-Learn ya ofrecía una amplia cantidad de transformers que permiten llevar a cabo distintas operaciones sobre nuestros datos. El problema es que, en el mundo real, es sencillo encontrarse datos en los que las distintas features son de diversos tipos, esto implica que los requisitos de preprocesamiento no serán los mismos para todas ellas. Es necesario, por tanto, aplicar transformaciones de manera focalizada según el tipo de cada feature. ColumnTransformer (aun en versión experimental) nos permite seleccionar a qué columna o columnas les será aplicada cada transformación. Veamos un ejemplo:
Definimos primeramente un dataframe nuevo. A diferencia de los ejemplos anteriores, en los que cada transformer se aplicaba a todas las columnas de cada dataframe, en esta ocasión definimos un ColumnTransformer que nos permite montar un pipeline. En este, indicaremos las transformaciones que se desean aplicar y a qué columnas deseamos aplicarlas. El primer parámetro es una lista de tuplas en la que cada tupla indica:
el nombre que nosotros le damos a la transformación (a nuestro gusto),
la definición del transformer
una lista con los índices de las columnas a las que afectará.
Una vez hayamos definido la lista de tuplas, especificaremos, mediante el parámetro remainder, lo que queremos que les pase a las columnas que no han sido afectadas por ninguna transformación: passthrough (si queremos que pasen al final del pipeline intactas), drop (si queremos que se eliminen del resultado).
Es interesante recalcar, aún más, que el funcionamiento del ColumnTransformer es como el de un pipeline. Por tanto podremos acceder a los “eslabones” de la estructura que hayamos especificado a través de las tuplas, mediante los nombres que hayamos utilizado para denominar cada una. Por ejemplo en el caso anterior:
Named_transformer_
La propiedad named_transformer_ devuelve un diccionario en el que cada clave corresponde con los nombres utilizados para definir los transformer (el primer elemento de cada tupla). Al acceder al diccionario utilizando uno de estos nombres estaremos accediendo a su vez a cada uno de los transformer definidos.
Incluso es posible construir un ColumnTransformer sin necesidad de especificar un nombre para cada transformación. Por ejemplo:
Esta vez, no hemos especificado nombre alguno para los transformadores definidos, scikit-learn los ha nombrado por nosotros y podremos acceder a ellos a través de los nombres generados.
Esperemos que algunas de estas novedades introducidas en scikit-learn, os resulten tan interesantes como a nosotros; seguro que en un futuro cercano os facilitarán el trabajo. De todos modos, id con cuidado ya que algunas partes todavía son experimentales.
Gracias al Master en Big Data Analytics 100% Online tendrás amplios conocimientos sobre las herramientas y técnicas analíticas necesarias para la modelización de los principales retos de negocio, con el fin de mejorar la toma de decisiones a través de los datos y el conocimiento.
Antonio Rodríguez Jurado (Data Scientist en Sum Mind y antiguo alumno del máster de Big Data Analytics de datahack) nos presentó en este evento de datahack Madrid su sistema de predicción de estacionamiento en "VADO PERMANENTE". Para llevarlo a cabo, aplicó los conocimientos que aprendió en nuestro máster.
En la charla, nos mostró los componentes principales del sistema. Además, explicó cómo entrenó una Red Neuronal con imágenes de ocupación del VADO para ejecutarlo en una Raspberry Pi que predice el estacionamiento irregular. Tras esto, informa de esa situación mediante un bot.
Luego nos mostró una demo en la que ejecutó el modelo con imágenes guardadas. Así, pudimos ver la interfaz y cómo se comporta. Finalmente, Antonio habló de las posibilidades de su sistema y respondió a todas nuestras preguntas.
Gracias al Master en Big Data Analytics 100% Online tendrás amplios conocimientos sobre las herramientas y técnicas analíticas necesarias para la modelización de los principales retos de negocio, con el fin de mejorar la toma de decisiones a través de los datos y el conocimiento.
Big Data Spain 2017, sorteamos 500€
datahack participamos en Big Data Spain 2017 como patrocinadores oficiales. Contamos con un stand en el que ofrecíamos, entre otras cosas, 500€ a todos los que se acercasen. "Aliméntanos con tus datos, nosotros te alimentaremos con 500€", esa fue nuestro lema. A todos aquellos que se pasaban les ofrecíamos obleas de 500€ para que se las comieran. Además de poder participar en un sorteo de 500€ en formación si rellenaban un sencillo formulario.
Big Data Spain es el mayor evento de Big Data que se celebra en España. Esta edición, con 70 ponentes y más de 13.000 asistentes que acudieron de diferentes partes del mundo, por lo que fue íntegramente en inglés. Dos días repletos de charlas y actividades relacionadas con Big Data, en Kinépolis, Madrid.
Rubén Martínez, uno de los speakers en Big Data Spain 2017
Entre los ponentes, se encontraba Rubén Martínez, de datahack labs. En su charla: "Attacking Machine Learning used in AntiVirus with Reinforcement" explicaba cómo hacer malware indetectable utilizando Reinforcement Learning. Una breve, pero muy completa explicación que podéis disfrutar del resumen.
Demos de Deep Learning en el stand de datahack
En el stand de datahack, además de ofrecer los 500€ y merchandising oficial. Realizamos demos de Deep Learning con nuestro robot Yaco. Que consistían en tracking de objetos y de detección de género y emociones, como ya se hizo en innodata 2017. Muchos fueron los curiosos que se acercaron al stand para ver las demos en funcionamiento. Como Holden Larau que probó la demo acompañada por su mascota Boo.
En definitiva, Big Data Spain 2017 fue una grata experiencia de la que salimos muy satisfechos. Ya estamos en marcha para empezar a preparar nuestra participación en Big Data Spain 2018. Como escuela de formación en Big Data y Analytics, y desarrollando proyectos de consultoría y robótica. ¡El año que viene, mucho más y mejor!
Dejando a un lado el Internet Of Things y las Smart Cities, otro de los aspectos que facilita el análisis rápido de grandes volúmenes de datos es el deep learning y la inteligencia artificial, software capaz de analizar datos en tiempo real y adelantarse a futuros problemas, aprendiendo a sacar sus propias conclusiones sin necesidad de un programador.
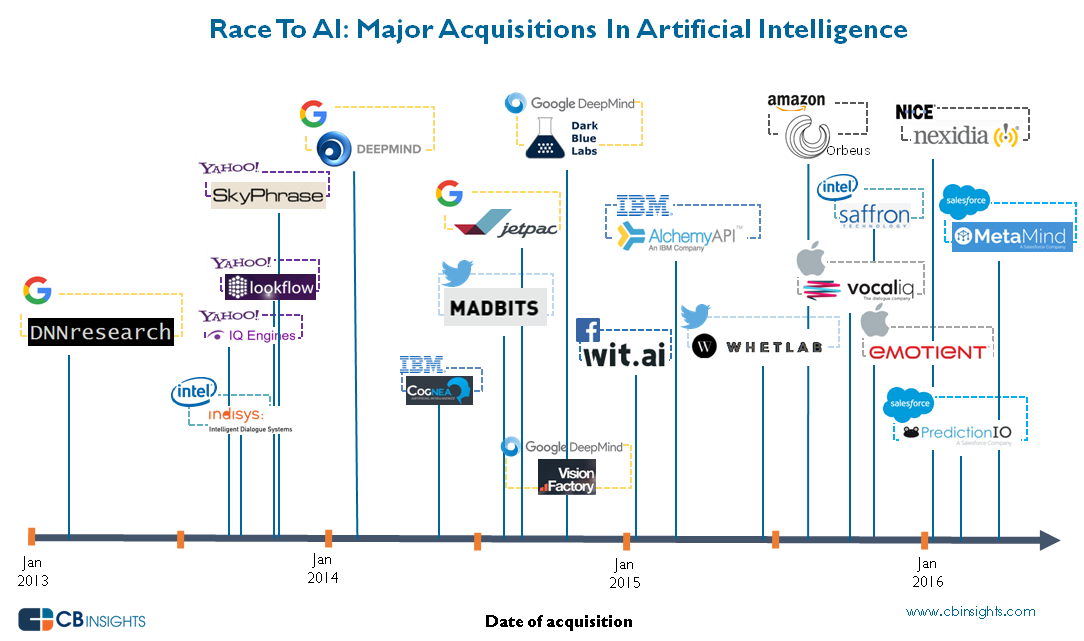
La prueba de que el sector de la inteligencia artificial es uno de los más prometedores en la tecnología de la información es el interés de las grandes empresas por adquirir startups del sector, como demuestra la creciente actividad de Google, Facebook, Apple, Intel o Amazon en este negocio, con cuatro compras destacadas en lo que llevamos de año.
Tal como indica el interesante artículo de CB Insights, más de 20 empresas privadas dedicadas a tecnologías avanzadas de inteligencia artificial han sido adquiridas por las grandes corporaciones en los últimos 3 años.
Inteligencia Artificial - línea cronológica de adquisiciones / FUENTE: CB Insights
Atendiendo a los rumores sobre un nuevo algoritmo para el buscador de Google capaz de reconfigurarse a sí mismo en función de las necesidades, el rey de los buscadores destaca como líder de la inversión en Inteligencia Artificial. De hecho, es el que más empresas ha adquirido, un 25% del total de empresas compradas. Entre estas incorporaciones destacan la compra en 2013 de DNNResearch, empresa especializada en Deep Learning y redes neuronales y fundada en la Universidad de Toronto, que le permitió a Google mejorar su buscador de imágenes. También destaca la adquisición en 2014 de la compañía británica DeepMind Technologies por unos 600 millones de dólares, cuya tecnología pudimos ver todos hace unos meses cuando el ordenador venció al campeón mundial del juego tradicional chino “Go”.
Amazon es otra de las multinacionales que compiten en el sector de la inteligencia artificial, enfocando su atención en el machine learning, con la adquisición de la californiana Orbeus. Salesforce se apuntó a la carrera en 2016, con la adquisición de dos compañías: MetaMind y el servidor de código abierto para machine learning ProductionIO.
Otras adquisiciones son, por ejemplo, Vision Factory, empresa dedicada al reconocimiento de textos y objetos mediante deep learning, por parte de Facebook; o Whetlab y Madbits por Twitter, dedicadas, respectivamente, a acelerar y mejorar los procesos de machine learning y a la identificación del contenido de imágenes mediante algoritmos de Deep Learning.
Si la inteligencia artificial es tu campo de interés, apúntate a nuestro máster Big Data, que culmina con un módulo de algoritmos avanzados de Deep Learning.
Resumen de privacidad
Esta web utiliza cookies para que podamos ofrecerte la mejor experiencia de usuario posible. La información de las cookies se almacena en tu navegador y realiza funciones tales como reconocerte cuando vuelves a nuestra web o ayudar a nuestro equipo a comprender qué secciones de la web encuentras más interesantes y útiles.
Cookies estrictamente necesarias
Propiedad
Cookie
Finalidad
Plazo
datahack.es
_btrid
Cookie necesaria para la utilización de las opciones y servicios del sitio web
en un año
datahack.es
_gat_UA-32658908
-1
Cookie necesaria para la utilización de las opciones y servicios del sitio web
Sesión
google.com
__Secure-1PAPISI
D
Cookie necesaria para la utilización de las opciones y servicios del sitio web
en 2 años
google.com
__Secure-1PSID
Cookie necesaria para la utilización de las opciones y servicios del sitio web
en 2 años
google.com
__Secure-3PSIDC
C
Cookie necesaria para la utilización de las opciones y servicios del sitio web
en un año
Si desactivas esta cookie no podremos guardar tus preferencias. Esto significa que cada vez que visites esta web tendrás que activar o desactivar las cookies de nuevo.
Cookies de terceros
Propiedad
Cookie
Finalidad
Plazo
datahack.es
_ga
ID utiliza para identificar a los usuarios
en 2 años
datahack.es
_gid
ID utiliza para identificar a los usuarios durante 24 horas después de la última actividad
en 20 horas
google.com
__Secure-3PAPISI
D
Estas cookies se utilizan para entregar anuncios más relevantes para usted y sus intereses.
en 2 años
google.com
__Secure-3PSID
Estas cookies se utilizan para entregar anuncios más relevantes para usted y sus intereses.
en 2 años
Publicitarias
Propiedad
Cookie
Finalidad
Plazo
datahack.es
_fbp
Utilizado por Facebook para ofrecer una serie de productos tales como publicidad, ofertas en tiempo real de anunciantes terceros
en 3 meses
datahack.es
_gcl_au
Utilizado por Google AdSense para experimentar con la publicidad a través de la eficiencia de sitios web que utilizan sus servicios.
en 3 meses
google.com
APISID
Descargar ciertas herramientas de Google y guardar ciertas preferencias, por ejemplo, el número de resultados de la búsqueda por hoja o la activación del filtro SafeSearch. Ajusta los anuncios que aparecen en la búsqueda de Google.
en 2 años
google.com
HSID
Descargar ciertas herramientas de Google y guardar ciertas preferencias, por ejemplo, el número de resultados de la búsqueda por hoja o la activación del filtro SafeSearch. Ajusta los anuncios que aparecen en la búsqueda de Google.
en 2 años
google.com
SAPISID
Descargar ciertas herramientas de Google y guardar ciertas preferencias, por ejemplo, el número de resultados de la búsqueda por hoja o la activación del filtro SafeSearch. Ajusta los anuncios que aparecen en la búsqueda de Google.
en 2 años
google.com
SID
Descargar ciertas herramientas de Google y guardar ciertas preferencias, por ejemplo, el número de resultados de la búsqueda por hoja o la activación del filtro SafeSearch. Ajusta los anuncios que aparecen en la búsqueda de Google.
en 2 años
google.com
SIDCC
Descargar ciertas herramientas de Google y guardar ciertas preferencias, por ejemplo, el número de resultados de la búsqueda por hoja o la activación del filtro SafeSearch. Ajusta los anuncios que aparecen en la búsqueda de Google.
en un año
google.com
SSID
Descarga ciertas herramientas de Google y guarda ciertas preferencias, por ejemplo, el número de resultados de búsqueda por página o la activación del filtro SafeSearch.
Ajusta los anuncios que aparecen en la Búsqueda de Google.
en 2 años
¡Por favor, activa primero las cookies estrictamente necesarias para que podamos guardar tus preferencias!
Cookies adicionales
Los servicios de terceros son ajenos al control del editor. Los proveedores pueden modificar en todo momento sus condiciones de servicio, finalidad y utilización de las cookies, etc.