Luis ha decidido ser Data Scientist. Desde hace tiempo lleva dándole vueltas a dedicarse a la inteligencia artificial, pero no sabe por dónde empezar. Tras consultar en Google y a ChatGPT qué herramientas son las más adecuadas para iniciarse, concluye que desde hace tiempo hay dos lenguajes de programación más utilizados en este mundo: R y Python. Luis decide dejar de lado debates eternos y decide aprender los dos, porque ¿existe acaso incompatibilidad? Tira una moneda al aire y el resultado es empezar por Python.
Senior Data Scientist y profesor de Python y machine learning en datahack
Autor del artículo
En resumen, Python sirve para todo, desde modelos de machine learning hasta para desarrollar YouTube. Para esto, Luis ve que Python se apoya en múltiples módulos, paquetes o “librerías”, “libraries” en inglés que son una ayuda para cada uno de los aspectos que se pueden utilizar con Python. En concreto para IA hay varias indispensables: Pandas, numpy, scikit learn, Keras, Matplotlib, Seaborn…. y unas cuantas más.
Por tanto, no basta con descargarse Python, sino que hay después que instalar múltiples bibliotecas o “librerías” para poder trabajar y, lo que es más complicado: cada librería depende a su vez de otras, lo cual hace que pueda haber incompatibilidad de versiones... y ¿cómo solucionar todo este lío? Cuando está a punto de tirar la toalla, Luis descubre Anaconda.
Anaconda es una distribución de Python (también de R), es decir, en lugar de instalar Python simplemente te instalas Anaconda y con ella ya tienes las principales herramientas Open Source que el Data Scientist necesita para desarrollar su actividad.
¿Cómo instalar Anaconda Python?
Instalar Anaconda es muy fácil; viene ya preparado para descargar el instalador según el sistema operativo que se quiera utilizar e instalarlo:
Cómo trabajar con Anaconda: Jupyter Notebook y Spyder
La instalación de Anaconda viene directamente con Jupyter Notebook como herramienta de notebooks y de Spyder como IDE de programación.
El Notebook es una herramienta muy habitual en el trabajo habitual del científico de datos. En su propia web se define como “Jupyter Notebook es una interfaz web de código abierto que permite la inclusión de texto, vídeo, audio, imágenes así como la ejecución de código a través del navegador en múltiples lenguajes. Esta ejecución se realiza mediante la comunicación con un núcleo (Kernel) de cálculo.”
Precisamente esa capacidad de poder incluir código junto con imágenes y texto es lo que hace particularmente adecuado para el análisis de datos, pues te permite llevar un hilo argumental a medida que se va llevando a cabo el estudio, los modelos, extrayendo las métricas, etc.
Sin embargo, los notebooks tienen una importante limitación: no permiten de modo fácil la productivización de los distintos algoritmos. Para esto es mejor recurrir a lo que se conoce como un IDE, es decir, un entorno para desarrollo integrado. Anaconda viene integrado con Spyder para lo que es la parte más de desarrollo y menos de análisis.
Una de las particularidades de Python como lenguaje Open Source es su continua evolución que puede hacer que desarrollos pasados que utilizaban ciertas versiones sean incompatibles con versiones más modernas. No solo casos ya extremos como una aplicación desarrollada con Python 2 que no funcione en Python 3, sino incluso métodos de librerías como pandas que se modifican o dependencias que cambian al actualizar las versiones.
Los entornos de Anaconda precisamente permiten manejar este tipo de situaciones. Un entorno de Anaconda se puede entender como un espacio aislado, independiente, donde las librerías y versión de Python se mantienen congeladas. Así, si tenemos un desarrollo muy importante que queremos seguir manteniendo con una combinación de versiones de librerías, lo ideal es tenerlo de modo estático o perenne en uno de estos entornos de anaconda.
Una de las recomendaciones a la hora de abordar proyectos es, precisamente, tener un entorno base con la instalación de Anaconda o incluso Miniconda (ya veremos la diferencia) y a partir de ahí, que cuelguen los diferentes entornos con las librerías requeridas para cada caso.
Los comandos más habituales para trabajar con entornos son:
Para crear un entorno: conda create --name nombre_entorno
Para crear un entorno con una versión concreta de python y una serie de librerías: conda create -n nombre_entorno python=3.6 pandas numpy matplotlib
Para activar un entorno existente: conda activate nombre_entorno
Instalación de librerías en Anaconda: Conda
Conda no es lo mismo que Anaconda: Conda es un gestor de paquetes, mientras que Anaconda es una distribución que, además de Python, incluye las librerías más habituales para el día a día del análisis de datos. Esto se traduce en que es Conda quien se va a encargar de manejar las distintas dependencias entre librerías de las que ya hemos hablado.
En resumen, es quien se va a ocupar cuando queramos actualizar una librería o instalar una nueva de que todo marche bien. La ventaja de habernos instalado Anaconda es que Conda viene integrado.
¿Esto significa que sin Conda no podríamos instalar nuevas librerías? No. Python incorpora un comando, Pip, que precisamente sirve para instalar nuevos módulos. Tanto Conda como Pip son válidos para instalar librerías, si bien, siempre que se pueda recurrir a Conda, merece la pena utilizarlo.
Por tanto, siempre que se quiera instalar una librería, podemos seguir los siguientes pasos que se van a ilustrar con un ejemplo. Supongamos que se desea instalar una librería que no viene por defecto con Anaconda, como puede ser Swifter.
Buscar si Swifter viene gestionado por Conda, sin más que recurrir a Google pregúntandole “conda swifter”:
Basta escribir “pip install swifter” en la línea de comandos:
Conclusión
El mundo de la Inteligencia Artificial y de la ciencia y análisis de datos está muy ligado a Python y esto implica, necesariamente, adaptarse a las particularidades de este mundo. Anaconda viene tanto a solucionar la entrada a los que se inicien en este apasionante mundo como a ser una herramienta imprescindible en el día a día para los científicos de datos más experimentados gestionando por nosotros entornos, librerías o paquetes etc. Desde luego, es una solución muy recomendable para el día a día del análisis de datos.
Estamos ya en el año 2023, y como podemos constatar en cualquier medio de comunicación, la inteligencia artificial vuelve a estar de moda. ¿Vuelve? Sí, porque en realidad este término se acuñó en el año 1956, y en los casi 70 años de historia que tiene ya esta rama de la tecnología, la misma ha evolucionado a una escala que difícilmente podría haberse pronosticado.
Desde sus inicios, la inteligencia artificial ha perseguido el objetivo de crear máquinas con una inteligencia similar o superior a la nuestra, con el fin de poder delegar trabajo cognitivo en ellas, o como apoyo para poder aumentar nuestra propia capacidad de pensamiento. Pero este objetivo es más un sueño que una meta bien definida porque, ¿qué es en realidad la inteligencia? ¿Cómo la definimos? Y, sobre todo, ¿cómo funcionan nuestros propios cerebros, esos que queremos imitar mediante tecnología? No lo sabemos con precisión.
Álvaro Barbero Jiménez
Chief Data Scientist del Instituto de Ingeniería del Conocimiento (IIC)
Autor del artículo
Es por esta indefinición que el foco de la IA y los métodos para abordarla han ido cambiando a lo largo de estas 7 décadas. En sus inicios, muchos investigadores en IA centraban sus esfuerzos en crear sistemas que pudieran replicar la capacidad de los humanos en tareas intelectualmente complejas: jugar al ajedrez, demostrar teoremas, realizar un diagnóstico médico en base las evidencias… se trataba de una forma concreta de implementar la IA, que hoy conocemos como sistemas expertos, y que tratan de realizar razonamientos empleando una base de datos de conocimientos y reglas, así como un sistema de inferencia basado en la lógica formal. Un ejemplo habitual de este tipo de sistemas sería el que dispone de la siguiente información:
hombre(x) ->mortal(x) (si es un hombre, entonces también es mortal)
hombre(Sócrates)= True (Sócrates es un hombre)
De lo que el sistema puede deducir mediante implicación lógica que mortal(Sócrates)=True (Sócrates es mortal). Esta clase de sistemas llegaron a utilizarse con éxito en campos como el diagnóstico de enfermedades infecciosas en la sangre. No obstante, en general este tipo de sistemas de IA resultaban ser difíciles de construir, dado que es necesario contar con expertos en la materia con los que colaborar para formalizar su conocimiento y métodos de trabajo en reglas formales. Así mismo, su mantenimiento y actualización a nuevas situaciones implicaba revisar su juego de reglas, una tarea que podía llegar a ser muy costosa en sistemas de gran tamaño.
Por otra parte, en torno a la misma época en la que se descubrían las limitaciones de los sistemas expertos, se llegó a una conclusión inesperada en cuanto al funcionamiento de la inteligencia: que las tareas que a los humanos nos resultan cognitivamente complejas, como los razonamientos matemáticos o la lógica formal, ¡son en realidad muy sencillas de implementar en un computador! Especialmente cuando se comparan contra el desafío de desarrollar una máquina con las capacidades sensoriales y motoras que puede tener cualquier niño con un desarrollo normal. Este hecho se recoge en la famosa paradoja de Moravec, y ha demostrado ser uno de los mayores obstáculos en del desarrollo de la IA: que las habilidades que a nosotros nos resultan intuitivas y naturales son las más difíciles de replicar de manera artificial.
Machine Learning
Una alternativa a los sistemas expertos de mayor aplicabilidad práctica y que se ha desarrollado con mucha solidez desde la década de los 80 es el aprendizaje automático o machine learning. En este tipo de IAs la clave radica en recopilar el conocimiento del experto no como una serie de reglas formales, sino como ejemplos que demuestren su forma de actuar. De este modo, podemos compilar una base de datos formada por casos médicos, en la que para cada caso recogemos la información utilizada el experto médico para su examen (constantes, analíticas, etc…), así como su diagnóstico, y el sistema de IA podrá aprender a imitar su forma de proceder. Dentro de este tipo de IA caben toda una variedad de algoritmos que afrontan este problema de aprendizaje empleando diferentes aproximaciones estadísticas: vecinos próximos, árboles de decisión, métodos de ensemble, máquinas de vectores de soporte, y muchos otros más.
Deep Learning
Uno de los métodos que ha destacado especialmente durante la última década han sido los basados en redes neuronales artificiales, hoy día también conocidos como Deep Learning. Aunque en realidad este tipo de IAs llevan en desarrollo desde incluso antes de que se acuñara el término “inteligencia artificial”, no fue hasta 2010 y años posteriores cuando se descubrieron las estrategias clave para poder construir sistemas de esta clase a gran escala: de ahí el calificativo “Deep”.
En esencia, las redes neuronales son un subtipo del aprendizaje automático, en el que una serie de neuronas artificiales imitan superficialmente el comportamiento de una neurona real, y se encargan de realizar la tarea del aprendizaje en base a los datos. Su principal ventaja frente a otros modelos de aprendizaje automático es su flexibilidad, ya que pueden construirse redes desde unas decenas de neuronas hasta miles de millones, escalando así su capacidad para aprender de bases de datos de tamaño masivo.
Además, esta flexibilidad del Deep Learning ha permitido a los investigadores en IA desarrollar “neuronas” especializadas en el tratamiento de datos no estructurados: imágenes, vídeos, textos, audio, etc… si bien esta clase de redes neuronales artificiales cada vez están más alejadas de la biología real, han demostrado ser tremendamente prácticas para abordar problemas muy complejos como son la detección de objetos de interés en imágenes (ej: personas, coches, …), la traducción automática entre idiomas, o la síntesis de voz. Con este hito se ha logrado abordar de manera muy efectiva la clase de desafíos sobre los que la paradoja de Moravec nos alertaba: aquellos que nos resultan intuitivos a nosotros, pero de difícil implementación en una máquina.
Foundation Models
¿Y qué podemos decir de estos últimos años? Sin duda, el avance más significativo en IA ha venido de la mano de los modelos base o foundation models. Se trata de un paso más en las redes neuronales artificiales, en el que redes de inmenso tamaño aprenden a modelar la dinámica de un proceso complejo mediante el análisis de bases de datos masivas.
Por ejemplo, un modelo base del lenguaje español es aquel que aprende cómo se estructura el idioma español y cómo suele usarse, mediante el procesado de gigabytes de textos escritos en este idioma. Este modelo no persigue un objetivo concreto, más allá de asimilar la estructura del lenguaje. Pero precisamente por eso puede alimentarse de cualquier texto escrito en el idioma, sin necesidad de que este haya sido preparado y validado por un experto, abriendo así la puerta a que la red neuronal pueda aprender de… básicamente todo el material que podamos suministrarle de Internet.
La pregunta que surge entonces es, ¿y para qué sirve un modelo así, si no tiene un objetivo práctico concreto? Pues porque como indica su nombre, sirven como base para crear modelos que apliquen a tareas concretas.
Por ejemplo, un modelo base del lenguaje español puede reajustarse a la tarea de analizar las emociones expresadas en un tweet, usando un conjunto de datos de tamaño medio con ejemplos de cómo hacer esta tarea. La ventaja de esta aproximación respecto de crear una red neuronal nueva que aprenda directamente de los datos es que el modelo base adaptado tendrá una efectividad mucho mayor, y requerirá de un juego de datos más pequeño para aprender a realizar su tarea. El motivo es que el modelo base ya conoce cómo se estructura el lenguaje español, y ahora solo le queda aprender cómo extraer la emoción de un texto en español.
Puede que los modelos base nos suenen a algo extraño, pero lo cierto es que están detrás de las IAs más famosas en la actualidad: GPT-3, ChatGPT, GPT-4, DALL-E 2, Stable Diffusion, … todas ellas utilizan de alguna manera u otra este concepto, y nos demuestran cómo aprender de fuentes de datos a tamaño Internet nos lleva a un tipo de Inteligencia Artificial muy superior a los vistos hasta ahora.
Deep Reinforcement Learning
Con todas estas IAs a la carrera, demostrando resultados cada vez más impresionantes, la pregunta que cabe hacerse es: ¿qué podemos esperar a partir de ahora? Internet es una fuente masiva de información, pero al mismo tiempo es limitada cuando se compara con la percepción que los humanos tenemos del mundo. Los estudios sobre modelos base han demostrado que a mayor número de datos podemos observar, mayor es la capacidad del sistema de IA resultante. Por tanto, el siguiente paso natural sería permitir que estos sistemas puedan aprender también de observaciones que hagan del mundo real, y más aún, que consigan a través de su propia experiencia. Este es el objetivo del aprendizaje por refuerzo profundo o deep reinforcement learning, el cual persigue que una red neuronal artificial pueda experimentar con su entorno y mejorar en una tarea a base de observar los resultados de sus experimentos.
Un ejemplo de este tipo de Inteligencia Artificial es AlphaZero, la cual consiguió alcanzar un rendimiento sobrehumano en el juego de tablero Go en tan solo 24 horas de aprendizaje, u OpenAI Five, que logró derrotar al equipo campeón del mundo en el e-sport DOTA2. Y fuera del mundo de los juegos, se han aplicado incluso para mejorar el control de un reactor experimental de fusión nuclear. ¿Será este el siguiente paso en la evolución de la IA? Aunque hoy día son sistemas muy costosos y complejos de aplicar en proyectos prácticos, alguna de las ideas que subyacen a su funcionamiento ya han sido incorporadas en ChatGPT y GPT-4, por lo que la tendencia parece clara.
Conoce más sobre IA en nuestro Máster Executive Inteligencia Artificial y Big Data
Es innegable que hoy en día tener conocimientos de programación es imprescindible. Hace años conocer y manejar adecuadamente el paquete Office “básico” (Word, Power Point, Excel) te permitía acceder a puestos laborales mejores que la media. Hoy en día y más después de la pandemia, la utilización de las herramientas Office es un fondo de armario que casi cualquier persona tiene conocimiento.
Pero, ¿qué pasa si quieres seguir formándote y desarrollando tus capacidades para, no solo acceder más fácilmente a otros puestos de trabajo, si no también para ser un profesional mucho más productivo y que puede aportar mejores soluciones tanto en el ámbito laboral como personal?
Desde mi punto de vista, lo mejor es formarte en algún lenguaje de programación que te permita automatizar y sistematizar tareas que, de otra manera, tendrías que ejecutar de manera manual y tediosa una a una.
Para todas aquellas personas que nunca han programado, uno de los mejores lenguajes para empezar es Python: un lenguaje de programación sencillo, fácil de comprender y con una curva de aprendizaje asequible que te permitirá poner a funcionar pequeños y no tan pequeños programas.
Antonio Fernández Troyanno
Responsable de proyectos Oficina de Transformación Bergé Logistics
Autor del artículo
Con el fin de ilustrar el potencial de Python, a continuación, te presentaré una serie de proyectos programados en Python para que veas el potencial de este magnífico lenguaje de programación.
ATENCIÓN: En este artículo vais a poder ver ciertos fragmentos de código que, si no tenéis conocimiento ninguno de programación, quizás pueda asustarte. Aleja esos terrores de tu mente, con un poco de trabajo y formación, verás que no es nada del otro mundo.
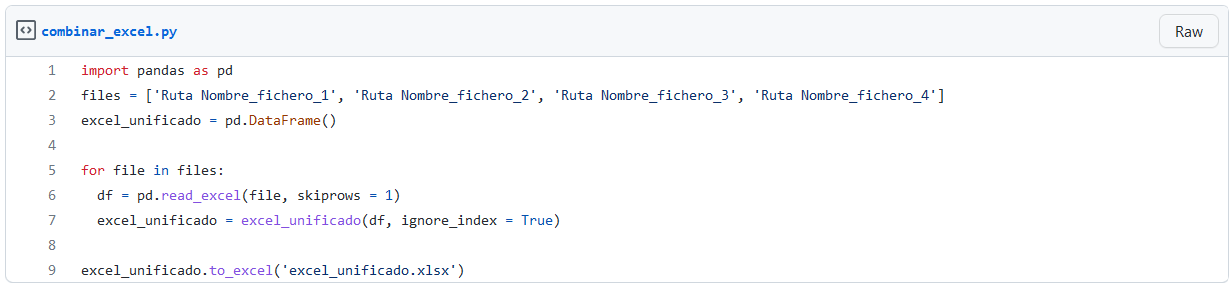
Manipular ficheros Excel sin utilizar Microsoft Excel
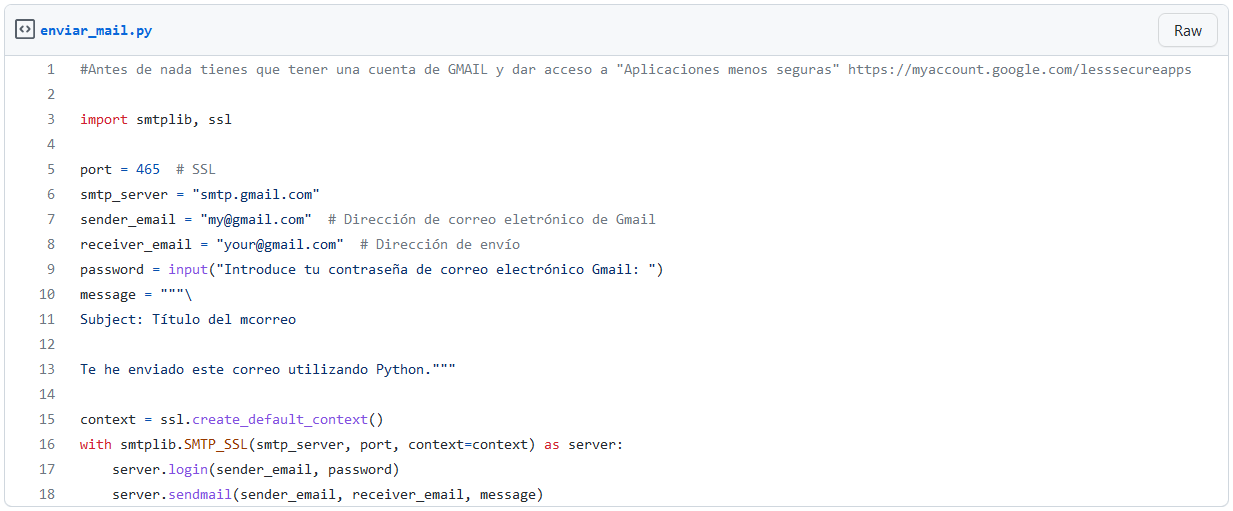
Enviar correos electrónicos desde Python
Modificar formatos de imágenes
Extraer información de páginas web y crear tu propio algoritmo de Machine Learning
¡Vamos con ello!
Manipular ficheros Excel sin utilizar Microsoft Excel
En muchas ocasiones nos surge la necesidad de concatenar o unir varios ficheros Excel de cientos o miles de líneas.
Imaginemos que cada mes se genera un reporte con información de financiera de la empresa, información de tus cuentas bancarias o cualquier otro ejemplo que se te pueda ocurrir.
Imagina que tenemos 12 ficheros Excel con sus mismas columnas y necesitamos unificar toda esa información en 1 solo fichero.
¿Qué soluciones tenemos?
Opción a) Abrir uno a uno cada fichero, copiar y pegar esa información y repetir esa tarea 10 veces más.
Opción b) Utilizar algún lenguaje de programación que nos permita simplificar esta tarea.
Sin duda, la opción a utilizar es la Opción b). Quizás inicialmente te lleve más tiempo programar en Python tu programa “UNIR EXCELS”, pero, ¿imagina que en lugar de 12 ficheros son 50? O, peor aún, que cada semana tienes que unificar 20 Excels….
¿No tiene sentido programar y automatizar esa tarea? Pues con Python podrías, y es mucho más sencillo de lo que parece…
¿Nunca te ha pasado que necesitas cambiar la extensión de una imagen y no sabes cómo hacerlo?
Buscas en Google como un loco y te sale un montón de servicios online, software de gratis pero con limitaciones, … ¿por qué no utilizar Python para esto?
Gracias a la librería de Python Pillow podremos, entre otras muchas cosas, modificar la extensión de nuestra imagen de forma rápida y sencilla (3 líneas de código…)
Extraer información de páginas web y crear tu propio algoritmo de Machine Learning
Y…. ¿si queremos algo más elaborado? ¡Pues aquí tienes! A continuación te presento un proyecto mucho más completo en Python en el que intentamos predecir el éxito que va a tener una noticia antes de publicarla analizando el éxito que tuvieron noticias pasadas.
El proyecto incluye:
Extracción automatizada de información de una página web
Tratamiento y limpieza de la información extraída
Tratamiento de lenguaje (NLP) Natural Language Processing
Entrenamiento de algoritmos de Machine Learning
Entrenamiento de una red neuronal
En este caso te un vídeo del proyecto completo sobre “Cómo predecir el éxito de una noticia mediante Machine Learning”
Y… ¡hasta aquí el artículo de hoy! Como ves estos son 4 ejemplos muy diversos sobre el potencial que tiene la utilización de Python a nivel profesional y personal, sin duda una herramienta muy potente e imprescindible conocer en el entorno de digitalización actual.
Atrévete a formarte con nuestroMáster Experto en Data Science y Big Data
Una formación 100% online y adaptada a ti para que te conviertas en un especialista en Inteligencia de Negocio
Microsoft Azure permite virtualizar máquinas, respaldar datos mediante backups, realizar analíticas, bases de datos, redes, almacenamiento y web, con una mayor rapidez, menor latencia, y ahorrando costes.
El día 5 de abril a las 18:30h datahack ofrece una sesión impartida por Borja Díez, sobre cómo utilizar el procesamiento en la nube para entrenar modelos de Machine Learning mucho más rápido y gastando lo mínimo.
Durante una hora, veremos una pequeña introducción a Azure, el servicio cloud de Microsoft, y cómo utilizarlo para hacer tareas básicas de data science a nivel usuario particular.
Para todo esto, aprovecharemos el crédito de bienvenida que te da la plataforma cuando al darse de alta para probar gratis.
La idea principal de esta sesión es explicar qué es Azure, las herramientas de Machine Learning que ofrece y cómo lo puede utilizar una persona sin conocimientos previos para hacer procesamientos más potentes de los que su ordenador puede soportar.
🔵 Durante el webinar podrás preguntar todas las dudas que tengas al ponente y las irá respondiendo. ¡No te quedes con ninguna duda!
🔵 Al registrarte recibirás un enlace en tu email con el que podrás conectarte a la sesión.
Cada vez es más habitual escuchar la palabra "Machine Learning", pero todavía muchas personas no saben qué significa y cuáles son sus funciones. En nuestro apartado de Actualidad aprenderás acerca de su función y sus categorías.
Machine Learning
¿Qué es el machine learning?
Es la capacidad de aprendizaje de una máquina mediante una serie de algoritmos y la entrada de datos a su sistema. Es una rama dentro del campo de la inteligencia artificial pero, a pesar de su nombre, no aprende por sí misma, sino por los patrones y la información recopilada por sus bases de datos. Estos algoritmos crean sus propios cálculos según los datos que consiguen y, cuántos más datos tienen, más precisas son sus acciones. Por este motivo, muchas personas creen que la inteligencia artificial se mueve sola, pero la realidad es que diseña sus propias respuestas mediante sus operaciones. Además, les permite tomar decisiones en base a predicciones.
El Machine learning es importante porque gracias a este software hemos facilitado la extracción de datos, lo que nos permite una mayor competitividad frente al resto de empresas. Los programadores especializados en estos ámbitos ya son capaces de diseñar modelos para analizar información compleja y obtener resultados rápidos y precisos sin necesidad de mano humana. De tal manera que la máquina por sí sola es capaz de realizar este trabajo.
3 categorías principales
Aprendizaje supervisado: es una forma de predecir con los datos de entrenamiento. El objetivo es entrenar al sistema de tal manera que es capaz de reconocer elementos desconocidos sin intervención humana. Se le incluyen datos previamente etiquetados y así la máquina puede clasificar los nuevos datos. También puede realizar el método regresión, en el cual, utilizando informaciones diferentes, puede predecir un resultado.
Aprendizaje no supervisado: este método permite conocer datos ya clasificados anteriormente mediante el uso de sus características. Es similar a la abstracción en humanos. Es un modelo que se ajusta a las observaciones. También es útil para la compresión de datos.
Aprendizaje por refuerzo: lo principal es la experiencia y es la unión del supervisado y no supervisado. Consiste en determinar qué acciones debe escoger un agente de software en un entorno dado con el fin de maximizar alguna noción de "recompensa" o premio acumulado. Como por ejemplo, un coche autónomo. Como está basado en la experiencia, es prueba y error.
Si tenéis alguna duda o sugerencia, en datahack estamos abiertos a recibir comentarios.
Más de 5 000 millones de personas participan a diario en interacciones en red que generan algún tipo de dato. Para 2025, esta cifra sobrepasará los 6 000 millones, lo que supone que el 75% de la población mundial formará parte de una gran muestra cuyo comportamiento estará en permanente estudio. Así lo ponen de relieve Seagate e IDC en su informe The Digitization of the World – From Edge to Core.
Este escenario que se nos dibuja para dentro de cinco años, con más de 150 000 millones de dispositivos interconectados -muchos de ellos recogiendo datos de manera ininterrumpida y en tiempo real- es un terreno abonado para el avance del Big Data y el Internet of Things (IoT) o Internet de las Cosas. ¿Qué puede ofrecernos la colaboración entre estos dos paradigmas?
Internet of Things (IoT): ¿qué es y cómo funciona?
Según el glosario de la consultora Gartner, el Internet of Things (IoT) o Internet de las cosas se define como una red de objetos interrelacionados y equipados con tecnología para la intercomunicación, la captura de señales o la interacción con el entorno. A día de hoy, el IoT se despliega en forma de millones de cámaras, grabadoras, ordenadores, móviles, radares, sensores, drones, códigos, termómetros, higrómetros, etc., que toman registros de lo que sucede y los envían a los centros de procesamiento.
Estos dispositivos presentan diferentes niveles de sofisticación. Los más sencillos como, por ejemplo, las etiquetas RFID, se emplean con fines de identificación. Otros, más complejos, actualizan su ubicación o son programables a distancia. Finalmente, hay nodos que, incluso, toman decisiones y las ejecutan por sí mismos si se cumplen ciertas condiciones.
Entonces, ¿qué relación hay entre el Big Data y el IoT?
La actividad del IoT da como resultado una cantidad ingente de datos que es preciso recopilar, validar, almacenar, procesar y analizar para extraer valor, es decir, conclusiones que nos permitan ampliar nuestro conocimiento y basar nuestros siguientes pasos. Es aquí donde, justamente, entra en juego el Big Data para, haciendo un símil con el mundo financiero, transformar en neto aquello que estaba en bruto.
IoT & Big Data: sectores de aplicación
La alianza entre Big Data e IoT proporciona ventajas en dos esferas: la industrial, con la implementación de soluciones B2B; y la del gran consumo, con desarrollos B2C que mejoran nuestra vida diaria en lo personal y en lo doméstico.
En el ámbito industrial, el IoT y el Big Data ya están presentes en sistemas automatizados de producción, en el sector del transporte, en la gestión de almacenes e inventarios o en el control de plagas y variables meteorológicas para la agricultura.
En la esfera individual, se hacen notar en los artilugios inteligentes (smartphones, smart TVs, wearables) y en la domótica.
Big Data e IoT, una alianza cargada de potencial de futuro
Extraer beneficios de la colaboración entre Big Data e IoT es cada vez más sencillo gracias a la suma de otras tecnologías, como el 5G, que ahorra ancho de banda en las operaciones y reduce la latencia en la transmisión de datos; y el edge computing, que favorece el procesamiento descentralizado de la información de manera que, cuando esta llega al nodo central de la red, lo hace ya desprovista de ruido y preparada para someterse a un proceso de análisis en Big Data.
Esta experimentación nos hace pensar en un presente y un futuro muy cercano en los que se registrarán considerables avances en campos como:
Inteligencia Artificial: gracias a los datos recabados por el IoT y a la aproximación a estos vía Big Data, será posible optimizar el entrenamiento de los modelos de machine learning y, como resultado, obtener inteligencias artificiales cada vez más potentes y autónomas.
Personalización de la experiencia de usuario: muy en boga en el mundo del marketing y el contenido digital, se basa en plantear a cada individuo un recorrido distinto en función de su comportamiento previo.
Smart Cities: reorganizar el tráfico, tomar medidas inmediatas para atajar la contaminación ambiental, reducir el despilfarro de agua, planificar mejor la política de urbanismo… Todo esto es posible en las ciudades que han sensorizado sus equipamientos y que sacan partido a los datos.
Mantenimiento predictivo de la maquinaria: un enfoque Big Data es capaz de monitorizar el desgaste una máquina y detectar las señales que, recogidas a través del IoT, anticipan fallos inminentes en el sistema.
Medicina preventiva: la adopción de los wearables abre un gran abanico de posibilidades para el fomento de hábitos saludables y el diagnóstico precoz de patologías latentes.
¿Te gustaría formar parte de la revolución del Big Data y el IoT que ya está en marcha? Nuestro Máster Experto en Arquitectura Big Data te prepara para desarrollarte profesionalmente en este sector, en el que podrás trabajar como líder de proyectos en sistemas intensivos de datos o como gestor de infraestructuras de Big Data, entre otras especializaciones. ¿A que suena bien? Pues no lo dejes para mañana: contacta con nosotros hoy mismo y te ofreceremos un asesoramiento personalizado.
En los últimos tiempos se ha producido una mejora considerable en la capacidad de procesamiento de datos, lo que supone un crecimiento exponencial en la cantidad de datos procesados. Por este motivo, el desarrollo de las herramientas de Big Data para analizar, procesar y almacenar los datos es un aspecto clave en la evolución de esta disciplina.
La evolución del Big Data gira en torno a tres conceptos fundamentales: Inteligencia Artificial (IA), Machine Learning y Deep Learning. La Inteligencia Artificial es un concepto englobador que se define como un conjunto de programas informáticos que imitan el comportamiento humano. Por su parte, Machine Learning y Deep Learning son modelos de IA basados en algoritmos que permiten realizar funciones específicas como reconocimiento de imágenes, elaboración de predicciones o procesado de lenguaje. Para llevar a cabo estas funciones, existen distintas herramientas de Big Data con características diferentes y concretas. A continuación, repasamos las más importantes.
Las 3 herramientas de Big Data más utilizadas
1. Spark
Es la herramienta de Big Data más potente para el procesamiento de grandes volúmenes de información. Así pues, no es de extrañar que sea el sistema de procesamiento de datos más utilizado por las empresas y organizaciones más importantes del mundo.
Spark es un motor de código abierto para el procesamiento de datos gestionado por la Apache Software Foundation. Entre sus principales ventajas destaca su organización en clústeres, que permite realizar operaciones sobre un gran volumen de datos. El sistema trabaja en memoria para conseguir una mayor velocidad de procesamiento.
Además, la plataforma Spark integra distintas soluciones para potenciar su rendimiento:
Spark SQL: módulo para el procesamiento de datos estructurados.
Spark Streaming: componente que posibilita la ingesta de datos en tiempo real mediante un proceso de gestión continuo.
Machine Learning Library (MLlib): biblioteca de algoritmos de Machine Learning para distintas finalidades como clasificación, regresión, análisis…
GraphX: API de procesamiento gráfico.
2. Hadoop
Esta herramienta de Big Data surge cuando Google se encuentra con la necesidad de procesar los datos a alta velocidad en un momento en el que el volumen de información disponible en la web experimenta un crecimiento exponencial. Para conseguir este objetivo, la estrategia del gigante online pasa por la creación de un sistema de archivos distribuidos o nodos. Así nace Hadoop, un sistema de código abierto impulsado por las nuevas exigencias del entorno digital. Sus principales ventajas son las siguientes:
Almacenamiento y procesamiento de grandes volúmenes de datos.
Alta velocidad gracias a su modelo de cómputo distribuido.
Tolerancia a fallos de hardware mediante la redirección de nodos en caso de error y la creación de copias automáticas.
Flexibilidad en el almacenamiento de datos no estructurados como imágenes, vídeos o textos.
Descubrimiento y análisis mediante un entorno de pruebas que permite la ejecución de algoritmos analíticos. Con una inversión mínima, las empresas y organizaciones pueden apostar por la innovación a través de la analítica en Big data.
3. Power BI
Power BI es una solución de inteligencia empresarial desarrollada por Microsoft. Permite recopilar información de diferentes fuentes en tiempo real y crear paneles, gráficos e informes compartidos por un gran número de usuarios. Se trata, por tanto, de una herramienta de Bussines Inteligente (BI) orientada a la monitorización de los datos relativos a una empresa u organización para su análisis y valoración en la toma de decisiones.
Entre sus funcionalidades destacan, además del almacenamiento masivo de datos, las capacidades de preparación y descubrimiento de datos, así como la creación de paneles interactivos completamente personalizables en función de las necesidades de cada usuario. Power BI integra distintas herramientas para la creación de informes como una aplicación de escritorio, una nube o un mercado de recursos visuales para hacer más atractivos los documentos. Además, cuenta con apps para iOS y Android y permite una integración completa con los servicios Office 365.
Aprende a utilizar las herramientas de Big Data más demandadas
En Datahack contamos con un profesorado experto altamente cualificado en distintas áreas de Big Data y Analytics. Si estás buscando una formación práctica y exigente, no dudes en contactar con nosotros, somos la escuela que buscas.
Actualmente estamos viviendo una auténtica revolución en el mundo de los bots. Y es que, desde que se empezó a hablar más de ellos, su número ha ido creciendo vertiginosamente. Son, cada vez más, los que se ven como una apuesta de futuro. Son algo que ha venido a definir un nuevo modelo de interacción entre las personas y las máquinas. En este artículo se van explicar las bases de las técnicas que están haciendo. También, por qué los chatbots se están convirtiendo en una plataforma conversacional tan innovadora y con tantas perspectivas de futuro.
LOS CHATBOTS Y SUS FORMAS DE ENTENDER
Lo primero es entender cómo los chatbots capturan, procesan e interpretan lo que le dice una persona. Usarán esta información para generar una respuesta. Para que un chatbot entienda lo que se le dice, existen dos técnicas:
Coincidencia de patrones
Clasificación de intenciones
Así, ante la siguiente frase “Me gustaría volar de Madrid a Dublín, el 14 de agosto”, y teniendo en cuenta que es un chatbot de viajes:
Coincidencia de patrones:
Con la técnica de coincidencia de patrones, sería necesaria una lista de los posibles patrones de entrada, por ejemplo: Me gustaría volar de <CIUDAD> a <CIUDAD> el <FECHA> Este tipo de técnica, más inteligible para los humanos, tiene el problema de que tiene que construirse manualmente y de forma estática. Es decir, se tienen que ir definiendo cada una de las posibilidades que se puedan dar.
Clasificación de intenciones
En la clasificación de intenciones se utilizan técnicas como el NLP (Natural Language Processing o Procesado de Lenguaje Natural) para interpretar los mensajes del usuario y detectar su intención. A la hora de trabajar con este tipo de técnica es importante tener claro que:
Los intents o “intenciones”: Son las piedras angulares de cualquier sistema de NLP, y sirven captar la intención implícita que hay en las frases del usuario. De esta forma, se puede relacionar lo que va diciendo con lo que el chatbot tiene que hacer. Y se corresponderían con los verbos de la frase.
Las entities o “entidades: Son los conceptos específicos de un dominio (nombre, lugar, fecha, profesión, etc.) y sirven obtener una información adicional que complementa al intent. Se corresponderían con los sustantivos de la frase. Normalmente pueden definirse intents y entities propias o usar las que ya vienen definidas en el sistema. La cantidad y variedad de las predefinidas dependerá de lo que haya establecido y de quién construya el sistema de NLP
Las actions o” acciones”: Serían los pasos que seguirá el chatbot, una vez se ha identificado la intención de la frase entrante. Cada intent tiene definidas sus propias acciones.
El “contexto de la conversación” o context: Se genera siempre que se inicia una conversación y sirve para ir estableciendo las circunstancias y valores que se dan en torno a la misma. De modo que una misma frase podrá gestionarse diferentes formas. Es decir, que su significado e intención podrá variar en función de las preferencias del usuario, su ubicación geográfica, el tema de la conversación o lo que se haya hablado con anterioridad en la misma. El subcontexto, o contexto que se generan a partir del contexto principal sirve para gestionar, de forma más concreta, la información que se crea o elimina durante la conversación. Por ejemplo, se puede usar la existencia de un subcontexto como requisito para poder usar un intent determinado.
Teniendo en cuenta este esquema, cuando un chatbot recibe una frase del usuario, buscará el intent que mejor se ajusta a la misma y teniendo en cuenta la información contenida en la misma, las entities identificadas y si hay definido un subcontexto (depende de la plataforma que se use). Tras determinar el intent se ejecutarán una serie de acciones (“actions”) para dar una respuesta al usuario.
Entonces, en base a la frase anterior: “Me gustaría volar de Madrid a Dublín, el 14 de agosto”. Un chatbot con NLP vería que habría un intent (Buscar Vuelo) y tres entities, dos de localización (Madrid y Dublín) y una de fecha (14 de agosto). Una vez identificado el intent, se ejecutaría un proceso de búsqueda de vuelos, teniendo en cuenta la información proporcionada por las entidades.
LOS CHATBOTS Y SUS DIFERENTES FORMAS DE RESPONDER
Una vez que el chatbot ha entendido lo que le dice el usuario, generará una respuesta en base al contexto de la conversación y la información que haya identificado en la misma. Los sistemas de generación respuestas pueden ser:
Estáticos: Los más sencillos. Las respuestas construyen en base a una serie de respuestas predefinidas que son elegidas y completadas según la información proporcionada por el usuario, por ejemplo: Hay un vuelo a las <HORA> que sale desde <AEROPUERTO> Donde las variables <HORA> y <AEROPUERTO> son generadas por el chatbot, teniendo en cuenta la información proporcionada. La elección de la respuesta correcta se hace en base a sistemas de expresiones regulares.
Dinámicos: Similares a los anteriores pero la elección de la respuesta se hace teniendo en cuenta técnicas basadas en algoritmos de Machine Learning. Estos construyen una respuesta en base al intent detectado. Estos dos sistemas son los más sencillos de implementar y los menos propensos a cometer errores gramaticales. No obstante, son incapaces de manejar casuísticas para los que no han sido pensados o entrenados previamente.
Generativos: Son aquellos que generan sus propias respuestas, sin necesidad de contar con un conjunto de respuestas predefinidas. Así, permiten establecer conversaciones más parecidas a las humanas, pero con una mayor propensión a los errores gramaticales. Se construyen usando técnicas de Deep Learning y son más difíciles de entrenar. A veces son necesarios millones de ejemplos para obtener unos buenos resultados. Aunque aún están en fase de investigación, tienen un futuro prometedor.
Productivización modelos machine learning. Mi modelo está listo ¿y ahora qué?
A estas alturas de la película, seguro que todo el mundo tiene claro ya que para pensar siquiera en productivizar nuestro modelo de Machine Learning. Su performance con respecto al conjunto de test (esos datos que desde un principio no se deben tocar, mirar, ni mencionar para no distorsionar la verdadera capacidad de generalización de nuestro modelo aspirante a pasar a producción) tiene que ser bueno. Esto quiere decir que, o bien mejore al modelo actual, o bien si no hay tal modelo, por lo menos descargue a las personas que actualmente se encargan de estimar lo mismo que el modelo, de esta tarea. De modo que puedan dedicar su tiempo a algo más provechoso.
Pues bien, si hemos conseguido lo comentado anteriormente, tendremos que presentar nuestro modelo a los jefes haciendo especial hincapié en los siguientes puntos:
¿Qué hemos aprendido de los datos?
¿Definir qué fue aquello que intentamos y funcionó peor?
¿Identificar qué fue aquello que sí que funcionó bien?
Posibles alternativas para mejorar el resultado actual y tiempo necesario para probarlas.
Una bonita presentación, con visualizaciones claras y frases concisas y fáciles de recordar del tipo “según el modelo actual la feature X, parece ser la que tiene más peso a la hora de predecir el label y”, será imprescindible también.
¡Perfecto! Nuestros jefes han quedado encantados, pero… ¿y ahora cómo ponemos el modelo en producción? Bueno, si has montado tu modelo en scikit-learn puedes optar por volcar a disco tu modelo entrenado, por supuesto incluyendo todo el pipeline de preprocesamiento de datos y de predicción.
Para ello podemos utilizar nuestro querido pickle, aunque para esta tarea, casi es preferible el uso de joblib más eficiente a la hora de tratar con objetos que internamente manejan grandes estructuras de numpy, como suele ser el caso de los estimators de scikit-learn.
El cómo desplegar nuestro modelo, dependerá del caso de uso. Por ejemplo, supongamos que nuestro modelo se vaya a usar en una página web de tal manera que el usuario introduzca o cargue algún dato (la entrada del pipeline), le daría a algún botón y esto provocaría que los datos se enviaran al servidor web, el cual a su vez los pasaría a nuestra aplicación web dentro de cuyo código se invocaría al método predict() del modelo.
Lógicamente la carga del modelo se tendría que realizar a la hora de arrancar el servidor, no cada vez que un usuario requiera una predicción.
Otra alternativa mejor es empaquetar el modelo en un web service, con el que nuestra aplicación pueda actuar a través de una API REST. Una de las ventajas de esto es que nos facilita el escalado, puesto que podremos arrancar tantos web services como necesitemos y balancear las peticiones procedentes de la aplicación web entre los web services existentes.
Dentro de la estrategia anterior, tenemos el caso particular de desplegar nuestro modelo en el Cloud, si por ejemplo optamos por Google Cloud Platform, podemos recurrir a Cloud IA (lo que antes se llamaba ML Engine) y hacer lo siguiente: subir el fichero joblib que hemos guardado a un bucket del Google Cloud Storage y dentro de Cloud IA, crear un modelo con su correspondiente versión, que apunte al fichero que hemos subido.
Si el modelo ya existía y queremos subir una nueva versión, el procedimiento sería el mismo solo que no habría que crear un modelo, sino una versión del mismo y luego asegurarnos que esta versión es la que está activa.
De esta manera tendríamos un web service simple, que se encargaría del escalado y el balanceo de carga por nosotros. Habría que tener en cuenta que los datos de entrada tendrían que venir en formato JSON y los datos de salida se devolverían en ese mismo formato. Luego ya sería usar este web service en nuestra web o en nuestro sistema de producción correspondiente.
Todo esto está muy bien, pero hay un lado más oscuro del que no se habla tanto y que es el del “babysitting” o monitorización del rendimiento de nuestro modelo.
No existe eso de, “entreno mi modelo lo despliego y ya está” …Es necesario invertir tiempo en escribir código que permita controlar el rendimiento de nuestro modelo periódicamente y enviar alertas cuando aquel decrezca.
Podremos encontrarnos con caídas fuertes y evidentes (por ejemplo, si falla algún componente de infraestructura) o con un deterioro paulatino más difícil de detectar a largo plazo.
Esto último es habitual ya que los modelos tienden a “deteriorarse” con el tiempo, lo cual es lógico: si nuestro modelo fue entrenado con datos de hace un año, es muy posible que no se adapte a los datos actuales.
Si lo piensas, incluso un modelo que haga algo tan aparentemente poco cambiante como clasificar fotos de gatos y perros puede requerir de un reentrenamiento regular.
Claro, esto no es porque los gatos y los perros muten de repente (en principio…), sino porque, por ejemplo, las cámaras utilizadas para tomar las fotos, junto con los formatos de imagen, contrastes y brillos, sí que tienden a cambiar cada cierto tiempo.
Sin mencionar el tema de las modas, razas que antes eran marginales y que de repente se vuelven tendencia…o circunstancias como que de repente surja la moda de poner chalequitos o gorritas a los pobres animales. Todo ello es motivo suficiente para que el rendimiento de nuestro sistema se vea afectado.
Descubre toda nuestra formación para poder desarrollar tus modelos de Machine Learning.
El análisis predictivo es uno de los usos más frecuentes del machine learning, dado que es de los más útiles para las necesidades de las empresas y organizaciones. Pero, ¿qué tipo de algoritmos se utilizan para hacer estos análisis y cómo funcionan? Aquí se muestran algunos de los algoritmos más utilizados en los modelos de predicción.
Regresión lineal
Consiste básicamente en una línea recta que muestra el “mejor encaje” de todos los puntos de los valores numéricos. También se llama el método de los mínimos cuadrados porque calcula la suma de las distancias al cuadrado entre los puntos que representan los datos y los puntos de la línea que genera el modelo. Así, la mejor estimación será la que minimice estas distancias.
Lo bueno es que es fácil de entender y se ve claramente el porqué de esa línea. No obstante, tiende al overfitting, siendo peligrosos los valores extremos. Aparte, es demasiado simple para capturar relaciones complejas entre variables.
Regresión logística
Es una adaptación de la regresión lineal a problemas de clasificación (booleanos, grupos…), utilizando el método de máxima verosimilitud para saber cuál es la probabilidad de que ocurra algo en cada punto determinado.
También es fácil de entender, pero, igualmente, tiene las desventajas de ser demasiado simple y de tender al overfitting.
El árbol de decisión
Es un gráfico que usa un método de ramificación basado en construcciones lógicas. Los árboles de decisión comienzan con el conjunto de datos completo y se van descomponiendo en distintas ramas en función de una serie de condiciones que se van seleccionando hasta llegar a la resolución del problema
Es muy fácil de entender e implementar, aunque resultan demasiado simples y poco poderosos para datos complejos.
Bosques aleatorios (Random forest)
Toma la media de muchos árboles de decisión hechos con muestras de los datos. Como se basa en muestras, cada árbol por separado es más débil que uno completo, pero la suma de todos logra unos resultados mejores.
Tiende a dar modelos de alta calidad, pero es difícil entender el porqué de las predicciones.
Potenciación del gradiente (Gradient Boosting)
Hace como el modelo anterior, pero usando árboles de decisión incluso más débiles. Luego, optimiza la muestra de datos utilizados en cada paso.
Tiene un alto desempeño, pero cualquier pequeño cambio en el conjunto de datos puede generar cambios radicales en el modelo, por no hablar de que es muy difícil comprender las predicciones.
Redes neuronales
Imitando el comportamiento del cerebro, son unidades (“neuronas”) interconectadas en varias capas que pasan mensajes de unas a otras. Se utilizan cuando no se conoce la naturaleza exacta de la relación entre los valores de entrada y de salida.
Pueden resolver tareas extremadamente complejas como reconocimiento de imágenes, pero son muy lentas, requieren mucha potencia y sus resultados son predicciones casi imposibles de comprender.
K-vecinos más cercanos (k-NN o Nearest Neighbor)
Es un algoritmo de agrupamiento (clutering) no jerárquico, de los más utilizados, aunque no el único. Mediante métodos estadísticos de reconocimiento de patrones, se calcula la distancia de un dato a los vecinos más cercanos del conjunto de entrenamiento. El resultado está basado en la probabilidad de que un elemento pertenezca a la clase.
El mayor problema que tiene es que funciona mal con muestras pequeñas.
Este algoritmo asume que la presencia o ausencia de una característica no está relacionada con la presencia o ausencia de cualquier otra. De este modo, cada una de las características del conjunto contribuye de forma independiente a la probabilidad de que el conjunto sea un objeto concreto.
Lo bueno es que solo requieren una pequeña cantidad de datos, aunque a menudo falla a la hora de producir una buena estimación de las probabilidades de clase correctas.
Algoritmos de reducción de dimensionalidad
Estos algoritmos no son predictivos como tal. Se utilizan para reducir el número de variables a analizar encontrando las que realmente son relevantes para el análisis. Por ello, muchas veces se utilizan junto a los algoritmos anteriores, especialmente en conjuntos de datos muy grandes.
Si te ha gustado este artículo ¡No olvides suscribirte a nuestra Newsletter!
Resumen de privacidad
Esta web utiliza cookies para que podamos ofrecerte la mejor experiencia de usuario posible. La información de las cookies se almacena en tu navegador y realiza funciones tales como reconocerte cuando vuelves a nuestra web o ayudar a nuestro equipo a comprender qué secciones de la web encuentras más interesantes y útiles.
Cookies estrictamente necesarias
Propiedad
Cookie
Finalidad
Plazo
datahack.es
_btrid
Cookie necesaria para la utilización de las opciones y servicios del sitio web
en un año
datahack.es
_gat_UA-32658908
-1
Cookie necesaria para la utilización de las opciones y servicios del sitio web
Sesión
google.com
__Secure-1PAPISI
D
Cookie necesaria para la utilización de las opciones y servicios del sitio web
en 2 años
google.com
__Secure-1PSID
Cookie necesaria para la utilización de las opciones y servicios del sitio web
en 2 años
google.com
__Secure-3PSIDC
C
Cookie necesaria para la utilización de las opciones y servicios del sitio web
en un año
Si desactivas esta cookie no podremos guardar tus preferencias. Esto significa que cada vez que visites esta web tendrás que activar o desactivar las cookies de nuevo.
Cookies de terceros
Propiedad
Cookie
Finalidad
Plazo
datahack.es
_ga
ID utiliza para identificar a los usuarios
en 2 años
datahack.es
_gid
ID utiliza para identificar a los usuarios durante 24 horas después de la última actividad
en 20 horas
google.com
__Secure-3PAPISI
D
Estas cookies se utilizan para entregar anuncios más relevantes para usted y sus intereses.
en 2 años
google.com
__Secure-3PSID
Estas cookies se utilizan para entregar anuncios más relevantes para usted y sus intereses.
en 2 años
Publicitarias
Propiedad
Cookie
Finalidad
Plazo
datahack.es
_fbp
Utilizado por Facebook para ofrecer una serie de productos tales como publicidad, ofertas en tiempo real de anunciantes terceros
en 3 meses
datahack.es
_gcl_au
Utilizado por Google AdSense para experimentar con la publicidad a través de la eficiencia de sitios web que utilizan sus servicios.
en 3 meses
google.com
APISID
Descargar ciertas herramientas de Google y guardar ciertas preferencias, por ejemplo, el número de resultados de la búsqueda por hoja o la activación del filtro SafeSearch. Ajusta los anuncios que aparecen en la búsqueda de Google.
en 2 años
google.com
HSID
Descargar ciertas herramientas de Google y guardar ciertas preferencias, por ejemplo, el número de resultados de la búsqueda por hoja o la activación del filtro SafeSearch. Ajusta los anuncios que aparecen en la búsqueda de Google.
en 2 años
google.com
SAPISID
Descargar ciertas herramientas de Google y guardar ciertas preferencias, por ejemplo, el número de resultados de la búsqueda por hoja o la activación del filtro SafeSearch. Ajusta los anuncios que aparecen en la búsqueda de Google.
en 2 años
google.com
SID
Descargar ciertas herramientas de Google y guardar ciertas preferencias, por ejemplo, el número de resultados de la búsqueda por hoja o la activación del filtro SafeSearch. Ajusta los anuncios que aparecen en la búsqueda de Google.
en 2 años
google.com
SIDCC
Descargar ciertas herramientas de Google y guardar ciertas preferencias, por ejemplo, el número de resultados de la búsqueda por hoja o la activación del filtro SafeSearch. Ajusta los anuncios que aparecen en la búsqueda de Google.
en un año
google.com
SSID
Descarga ciertas herramientas de Google y guarda ciertas preferencias, por ejemplo, el número de resultados de búsqueda por página o la activación del filtro SafeSearch.
Ajusta los anuncios que aparecen en la Búsqueda de Google.
en 2 años
¡Por favor, activa primero las cookies estrictamente necesarias para que podamos guardar tus preferencias!
Cookies adicionales
Los servicios de terceros son ajenos al control del editor. Los proveedores pueden modificar en todo momento sus condiciones de servicio, finalidad y utilización de las cookies, etc.